
Perché l'Algoritmo Non è Quello Che Pensi

Perinetti non è convinto di Ghisolfi perché "usa un algoritmo per scegliere i giocatori". Per Manna "il numero fine a sé stesso è un numero", Lotito invece chiede: "cosa ne sa un algoritmo dei valori umani di un atleta?"
Quando sento parlare di algoritmi, nel calcio italiano, trovo sempre la stessa confusione. E la cosa non mi sorprende. Nasce dalla pigrizia di chi infila algoritmo in titoli, domande, risposte. Di chi lo usa per provocare il sentimento antagonista dei tifosi, per guadagnarci qualcosa. Click, apprezzamento delle folle, sai tu.
Ma qualcuno si è mai chiesto cosa siano sti algoritmi?
Partiamo dal termine: Treccani dice che deriva da al-Khuwārizmī, usato nel 9° secolo per descrivere un procedimento sistematico di calcolo.
La definizione pura è: sequenza finita di operazioni. Dici algoritmo e pensi al mondo informatico, ma in realtà si applica bene anche in altri contesti: e se ti dicessi che anche il lavoro di allenatori reticenti dipende dall'efficacia di algoritmi che creano loro stessi?
Pensa a come nasce uno schema su corner: è una sequenza strutturata di operazioni dove ogni movimento è progettato per manipolare la difesa avversaria.
L'allenatore definisce input (posizioni iniziali), regole di movimento (chi si muove e quando) e output atteso (creare le condizioni ideali per creare pericolo). Come in ogni algoritmo complesso, il risultato emerge dall'interazione tra istruzioni e contesto: tempismo dei movimenti, reazione della difesa, precisione dell'esecuzione.
Quando si guarda ai dati per individuare giocatori, la situazione è ancora più complessa.
Più che trovare l'algoritmo perfetto, più che individuare il numero da scrivere su un post-it per il direttore sportivo, l'obiettivo è cercare di sviluppare modelli progettati per rispondere a domande specifiche:
- Quanto è efficace un giocatore nel creare occasioni da gol?
- Come influenza il gioco della squadra quando non ha la palla?
- Le sue decisioni in campo sono sistematicamente corrette, al di là del risultato immediato?
I club che riescono a ricavare di più dai dati sanno usarli per entrare nel dettaglio. Ma in che modo?
Facciamo un passo indietro.
Di statistiche aggregate, tiri e xG sai già: utili ma non bastano. Per ricavare informazioni di alto valore su un giocatore, con i dati, c'è bisogno di modelli più curiosi che permettano di dare valore ad ogni singolo contributo. L'idea alla base è chiara: ogni azione in campo modifica le probabilità di segnare o subire un gol. E l'insieme di queste azioni aiuta a capire meglio il contributo di un singolo giocatore.
Partiamo dalla base.
Se vuoi capire quanto pericolo crea un giocatore, allora puoi partire dall'Expected Threat (xT). I modelli xT dividono il campo in zone, ognuna con un valore basato su quanto spesso le azioni partite da lì portano a un gol. Quando un giocatore sposta la palla - con un passaggio o una conduzione - il valore xT misura la differenza tra il valore della zona di partenza e quello della zona d'arrivo.
Utile? Sì.
Troppo specifico per essere usato nello scouting? Anche.
Sviluppare modelli ancor più ricchi, però, non è facile. E allora molte squadre si affidano all'On-Ball Value (OBV) di StatsBomb.
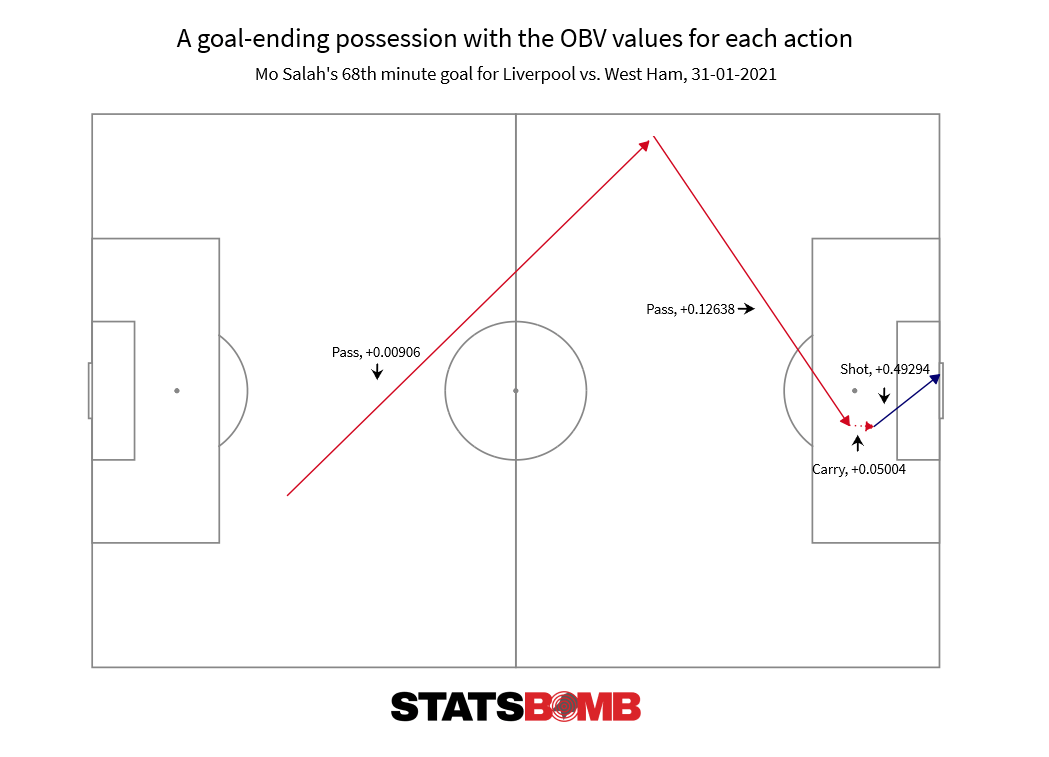
Rispetto ai modelli xT non si limita a vedere dove va la palla, ma considera come ci arriva. Un passaggio filtrante vale più di un lancio lungo nella stessa zona perché più preciso e controllabile. Una conduzione palla ha più valore se fatta superando la pressione avversaria. OBV aggiunge il contesto tecnico alla pura geografia del campo.
Più completo? Sì.
Esaustivo? Non ancora.
Puoi aiutarti in fase di scouting? I numeri sono gli stessi per te e il direttore sportivo della squadra contro cui competi ogni anno. Fai tu.
Con xT e OBV siamo ancora limitati alla giocata individuale, però. Manca quel contesto che invece trovi nei modelli Expected Possession Value (EPV).
Qui non si guarda più solo all'azione isolata, ma all'intera sequenza di possesso. EPV calcola continuamente la probabilità di segnare durante il possesso e misura come ogni tocco di palla la modifica. Quel passaggio all'indietro poco pericoloso potrebbe assumere un valore più alto, con questo modello, se ha attirato il pressing creando spazi per le azioni successive.
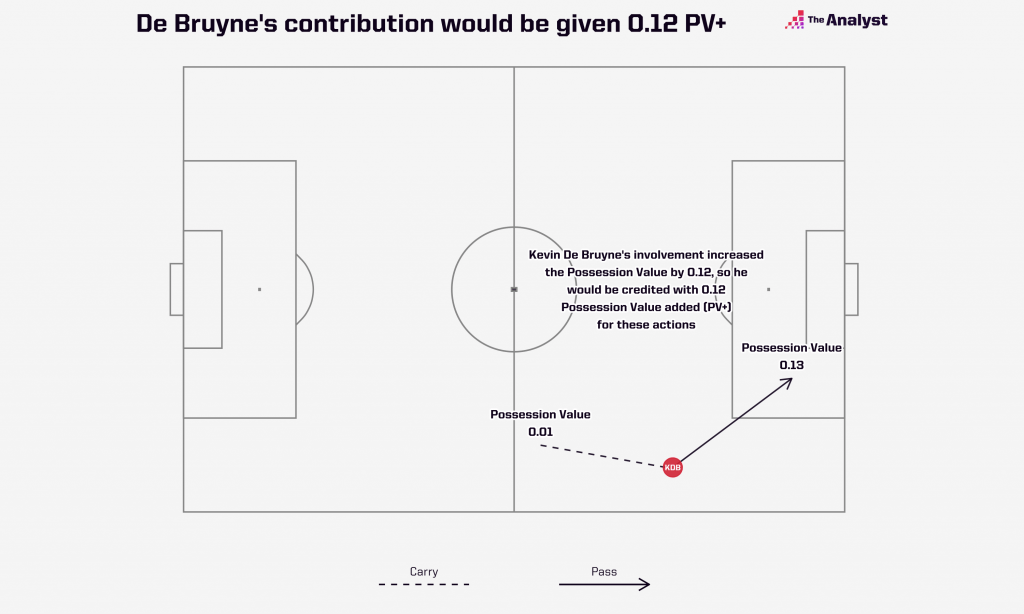
Ci siamo quasi, no?
I modelli si fanno più completi, le informazioni più vicine alla realtà del campo.
Eppure neanche l'EPV è così completo. Se l'obiettivo è capire l'impatto di un giocatore sul rendimento della squadra, dobbiamo considerare anche come le sue azioni incidono sulla probabilità che siano gli altri a segnare.
I modelli VAEP (Valuing Actions by Estimating Probabilities) sono i più completi perché guardano a ogni singola azione come un momento che può spostare l'equilibrio della partita in entrambe le direzioni.
Non si chiedono semplicemente "questa azione ci avvicina al gol?", ma "questa azione come modifica le probabilità che segni la nostra squadra rispetto a quella avversaria?". Analizzando migliaia di situazioni simili, VAEP valuta se un'azione aumenta più la probabilità di segnare o quella di subire gol.
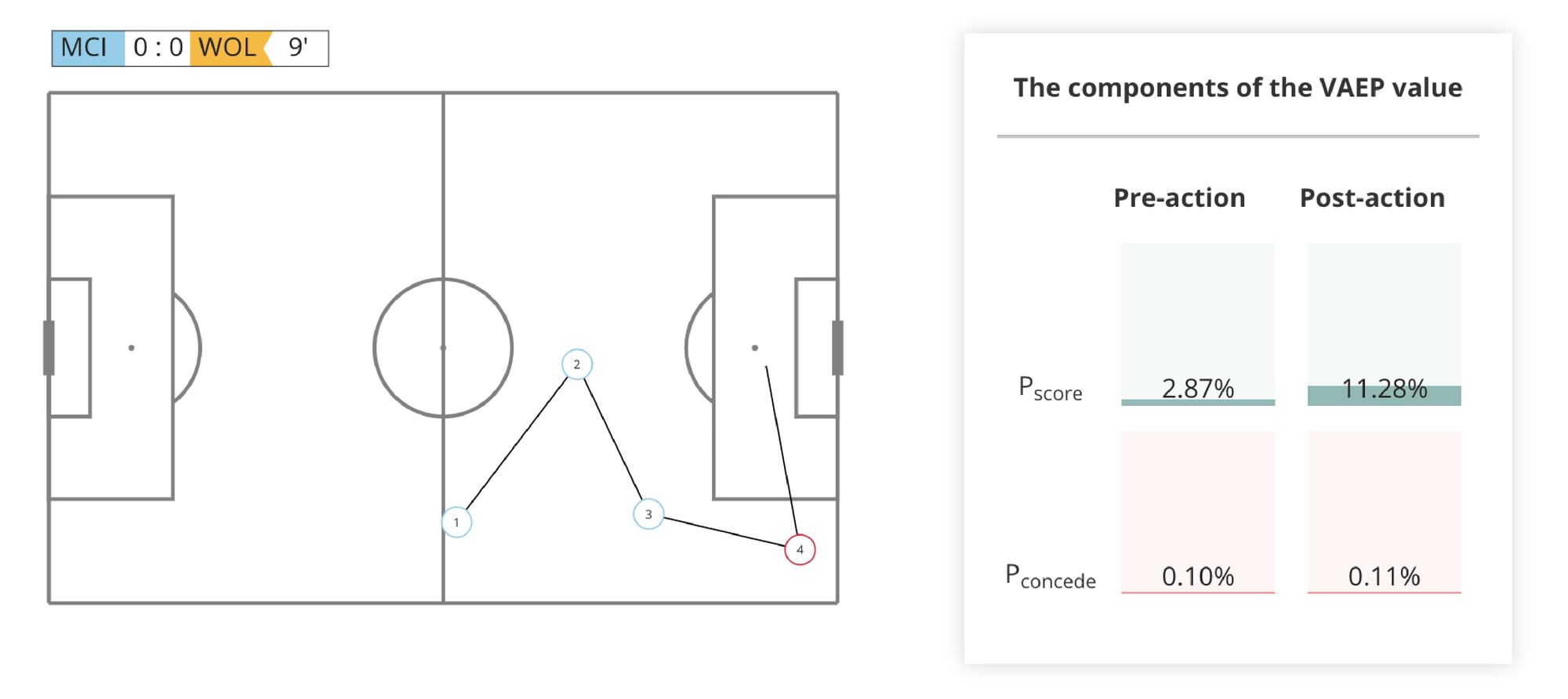
La differenza tra questi approcci è sostanziale. Ti faccio capire cosa intendo con un esempio che uso spesso: un mediano riceve palla sotto pressione, si gira superando la linea di pressing e serve un compagno tra le linee.
Come valutano questa azione i vari modelli?
xT valuterebbe principalmente lo spostamento geografico della palla, misurerebbe il cambio di pericolosità tra la zona di ricezione e quella del passaggio finale.
OBV aggiungerebbe alla valutazione la complessità tecnica dell'esecuzione: la ricezione orientata sotto pressione, il dribbling per liberarsi, la precisione del passaggio finale.
EPV guarderebbe oltre, valutando come quella sequenza ha modificato la struttura difensiva avversaria e la probabilità di segnare nelle fasi successive del possesso.
VAEP, infine, peserebbe l'intera azione nella sua duplice dimensione: quanto ha aumentato le nostre chance di segnare superando la linea di pressing, ma anche come questo ha modificato gli equilibri complessivi della partita (anche il modello OBV di StatsBomb calcola la probabilità di subire gol ma non considera l'intera sequenza di possesso o il valore di chi riceve palla).
Usare l'algoritmo, criticare l'algoritmo, essere scettico dell'algoritmo, non vuol dire niente, quindi, se non sai da dove arriva, come nasce, quali dati utilizza.
Il valore delle informazioni che puoi ricavare dai modelli dipende dalla natura stessa del modello e dalle sue fonti. Ma esistono contesti in cui quelle informazioni sono così utili da sostituire lo scouting tradizionale?
Come integrare scouting e dati
Quando cercano di convincerti che una squadra ha scelto un giocatore per l'algoritmo, non credergli.
Gli acquisti nascono da processi di selezione che coinvolgono sia scouting tradizionale che strumenti analitici (quando non influenzati da rapporti con agenti o da quell'incompetenza dirigenziale che sai cosa? Diamo la colpa all'algoritmo così ci salviamo tutti).
Anche perché i modelli citati prima hanno dei limiti, quando costruiti soltanto sui dati evento.
Sono quei dati che registrano cosa è successo ma a cui manca il contesto. Non vedono il movimento che ha creato lo spazio per quel passaggio. Non sanno se quel dribbling nasce contro una difesa schierata o in campo aperto. Non registrano se quella palla persa è frutto di un errore tecnico o di una scelta tattica rischiosa ma necessaria.
Ah, allora lo scouting tradizionale serve ancora?
Serve, sì. Soprattutto quando i modelli sono limitati da fonti dati ricche, ma incomplete.
Lo scouting tradizionale permettere di cogliere altri dettagli: l'intelligenza tattica nel movimento, il linguaggio del corpo. Può valutare come un giocatore si comporta in situazioni diverse, come reagisce alla pressione, come si adatta a sistemi di gioco differenti.
La convivenza potrebbe sembrare raffazzonata, da fuori, ma l'integrazione tra i due mondi è alla base dei club più efficaci in fase di mercato. Funziona in modi diversi, a seconda del club.
Al Brentford i numeri servono da filtro iniziale. L'obiettivo è identificare giocatori sottovalutati in mercati spesso trascurati. Aiutano a ridurre un database di migliaia di calciatori a una lista gestibile di potenziali obiettivi.
Lo scouting tradizionale conta, quindi. Ma viene utilizzato in modo mirato. Gli scout non partono da zero, ma valutano giocatori già "pre-selezionati" dai modelli. Risorse e competenze possono essere concentrate per analizzare aspetti che i dati non possono catturare.
Il Brentford lavora in questo modo da anni, ma il loro è un approccio comune anche in squadre che iniziano l'anno pensando a quanti trofei potranno raccattare.
Altri club hanno sviluppato approcci differenti. C'è chi parte dallo scouting tradizionale e usa i dati come supporto e validazione. Chi ha creato sistemi che integrano fin dall'inizio le due componenti. Chi usa i dati per alcune posizioni (per esempio gli attaccanti, dove i numeri sono più indicativi) e si affida più allo scouting per altre (come i difensori, dove le statistiche tradizionali catturano meno sfumature).
La chiave non sta nel trovare un equilibrio perfetto tra dati e scouting, ma nel costruire un processo che sfrutti i punti di forza di entrambi:
- I dati per identificare tendenze, scovare opportunità, dare struttura alla ricerca
- Lo scouting per valutare il contesto, analizzare gli aspetti attitudinali e tattici, capire il potenziale di sviluppo
Non è un caso che i club più innovativi abbiano investito tanto nella struttura quanto nel processo: database proprietari che integrano dati statistici e report degli scout, sistemi di ranking dinamici che combinano metriche oggettive e valutazioni qualitative, piattaforme che permettono di confrontare giocatori su più dimensioni.
Il segreto è l'integrazione, quindi?
Fino a un certo punto.
Anche lo scouting ha i suoi punti deboli. Lo scout è un essere umano, Claudio Lotito. E gli essere umani sono pieni di bias, Claudio Lotito.
La valutazione può essere influenzata da prestazioni particolarmente positive o negative o da come il singolo scout aveva valutato un giocatore simile in passato. È difficile mantenere lo stesso metro di giudizio su centinaia di giocatori in contesti diversi.
Ed è qui che i dati tornano utili: offrono un punto di riferimento costante, una base oggettiva per confrontare le prestazioni.
Le limitazioni dei modelli basati sui dati evento possono essere aggirate quando integrate con i dati tracking. Quando alle informazioni sugli eventi si aggiunge il contesto attorno all'evento.
In che modo?
Potenziando i modelli che ti ho introdotto prima. Ma anche aumentando le possibilità di analisi.
L'integrazione con i dati evento permette di lavorare con una fonte ricca, completa e inclusiva del contesto dietro a ogni azione.
La dicotomia occhio-dato sparisce se quel dato è arricchito dal tracciamento. I dati tracking sanno dove sei e dove sono gli altri, che spazio copri e come lo vuoti.
Pensa a un passaggio riuscito: i dati evento ci dicono solo che è partito dal punto A ed è arrivato al punto B. Ma qual era la difficoltà reale di quel passaggio?
Con i dati tracking abbiamo più informazioni: quanti avversari c'erano tra i due punti, quanto spazio aveva il giocatore per effettuare il passaggio, sotto che tipo di pressione stava giocando.
Non solo. I dati tracking permettono di misurare aspetti fondamentali del gioco moderno:
- Quanto spesso un terzino si sovrappone internamente invece che esternamente
- Quanti metri di spazio libero crea un attaccante per i compagni attirando su di sé i difensori
- La frequenza e velocità con cui un esterno attacca lo spazio alle spalle della difesa
- La densità di pressione che un centrocampista riesce a gestire quando riceve palla
Ci sono club che, sull'integrazione tra dati evento e tracking, hanno costruito squadre capaci di salire di categoria, di rivoluzionare la propria storia sportiva ma anche di fare cose comuni come vincere Premier e Champions League.
Di Liverpool, dati e astrofisici avrai già sentito parlare. Ma cosa rendeva il loro approccio così innovativo?
Il team di Graham aveva aggiunto alla capacità di valutare le singole azioni quella di analizzare l'efficacia delle decisioni dei giocatori in campo. Anche grazie all'integrazione dei dati tracking.
I vantaggi si sono fatti sentire soprattutto in fase di mercato.
Siamo nell'estate 2015, Klopp non è ancora arrivato ma l'idea è già quella di andare oltre Borini e Balotelli.

Il Liverpool vuole un attaccante capace di garantire intensità senza palla, ma capace di prendere decisioni giuste in momenti caotici come quelli successivi a una transizione.
Graham e il suo team, quindi, usano dati e modelli di reinforcement learning per valutare le azioni di pressing concentrandosi sulla qualità delle decisioni, piuttosto che solo sui risultati.
Il reinforcement learning aiuta a modellare il gioco come una serie continua di decisioni dei giocatori, assegnando valore alle scelte che migliorano le probabilità di successo della squadra nel lungo termine - che sia segnare o impedire un gol.
In questo caso, quindi, il modello non valuta solo l'esito immediato del pressing, ma anche come quella decisione influenza le probabilità di recuperare palla nelle fasi successive del gioco.
Il team di Graham ha integrato questo approccio con l'EPV: non solo quanto vale recuperare palla qui, ma quali decisioni nel pressing portano più probabilmente a situazioni vantaggiose. Analizzando migliaia di sequenze di pressing, il modello imparava a riconoscere i pattern decisionali che massimizzavano il valore atteso nel lungo termine, non solo il successo immediato del tentativo di recupero.
Permetteva quindi di rispondere a domande come:
- Tempismo del Pressing: Il giocatore ha pressato al momento giusto o si è sbilanciato lasciando spazio alle spalle?
- Consapevolezza Posizionale: L’azione di pressing ha costretto l’avversario in una zona meno favorevole o ha portato a un contrattacco pericoloso?
- Coordinazione: Il pressing è stato sincronizzato con i movimenti dei compagni o ha esposto falle nella struttura difensiva?
Senza un modello come questo, le valutazioni sarebbero rimaste soggettive.
La possibilità di quantificare il lavoro senza palla in fasi di pressing, invece, gli ha permesso di spendere £29 milioni per Roberto Firmino senza aver paura di aver fatto una cazzata.
Costruire modelli avanzati su basi più solide – dati tracking + dati evento – ti permette di quantificare anche quanto spazio crea un singolo giocatore, in che modo, e con quale esito.
Un anno dopo Firmino, un altro modello avanzato ha permesso al Liverpool di convincersi ad acquistare Mané.
Il pitch control sviluppato da Will Spearman è un modello di analisi spaziale che quantifica come i giocatori controllano lo spazio in campo utilizzando posizione, velocità e direzione di movimento di tutti i giocatori.
Non si limita a valutare il posizionamento statico, ma analizza come i movimenti dei giocatori influenzano dinamicamente il controllo di ogni zona del campo.
Nel caso di Mané, il modello mostrava non solo dove si posizionava, ma come le sue scelte di movimento alteravano il controllo dello spazio dell'intera squadra avversaria, creando opportunità che modelli tradizionali non potevano cogliere.
È questo il punto: l'algoritmo non sa valutare i valori umani di un atleta perché non è quello il suo scopo. I modelli che ti ho raccontato non aspirano a valutare la persona. Cercano invece di quantificare aspetti specifici del gioco che prima erano dominio esclusivo della valutazione soggettiva.
Le caratteristiche personali, la mentalità, l'adattabilità a un nuovo contesto restano territorio dello scouting tradizionale e dei network di relazioni.
I club più efficaci lo hanno capito: non è questione di scegliere tra dati e scouting tradizionale, ma di usare ognuno per ciò in cui eccelle.
Per chi vuole approfondire
- Liverpool FC data scientist William Spearman's masterclass in pitch control
- VAEP: An Objective Approach to Valuing On-the-Ball Actions in Soccer
- A framework for the fine-grained evaluation of the instantaneous expected value of soccer possessions





Member discussion